Justin Sapun, justin.sapun.th@dartmouth.edu
Miles Hudgins, miles.b.hudgins.25@dartmouth.edu
Maria Cristoforo, maria.h.cristoforo.24@dartmouth.edu
Through a four-stage development process, our objective was to design and implement a tiny search engine (TSE) with functionalities similar to that of major search engines like Google. The steps involve creating a web crawler for data acquisition, developing an indexer for word frequency analysis, implementing a querier to score and return query responses, and ultimately optimizing performance through multi-threading. The project emphasizes UNIX tools, C programming, testing, debugging, and collaborative teamwork in software development.
Implementation
We began this project by implementing linked lists, queues, and hashtable data structures to aid in our construction of the TSE. We also took the time to understand how to utilize given utility functions for downloading, saving, and loading web pages. Our work was done using an SSH and version control was managed by GitHub. Valgrind was used to ensure no memory leaks at each stage.
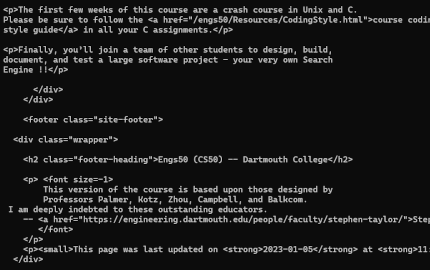
In this stage, we focus on the initial element of the search engine: the crawler. The program begins by retrieving the seed webpage, extracting embedded URLs, and converting them to a standardized format. Then, it recursively fetches each page found, saving the associated files to a specified directory. Pages are stored in the file system as sequentially numbered files (1, 2, 3, etc). The search depth is constrained to a specified level. In the image to the left, you can see the HTML contents of an example page.
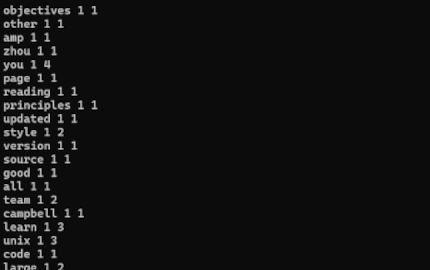
The next stage introduces an indexer to the TSE. The indexer parses the HTML content of each webpage fetched by the crawler and then constructs an index data structure. This structure makes looking up words easy by revealing the documents in the crawler directory that contain the word and the frequency of its occurrence in each document. Additionally, the index operates as a hash table of words, with each word linked to a list of entries. An example to the left showcases the entries: words with the document id first followed by the word’s frequency in that document.
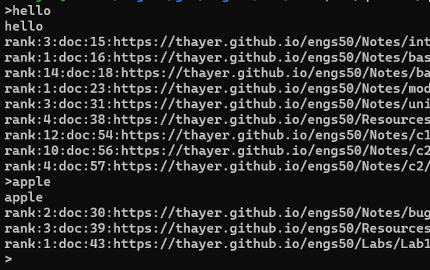
Our next step was to build a querier. The querier takes in user queries (from a file or command line), references the index created by the indexer, and then ranks documents fetched by the crawler based on relevancy. Afterward, it prints a list of documents in descending order of rank. We built our querier on the notion that Boolean operators AND and OR imply a search for pages containing all specified words or either of the specified words. The default connection between words is AND. In the demo example, you can see we query “muse and subject” which only returns one webpage (reachable from the seed URL) containing both those words.
The last stage of our project was to implement multithreading using pthreads and giving a user the flexibility to specify the number of threads using an extra command line argument. We chose to implement this for the indexer, which meant threads would simultaneously construct the index by scanning pages in the crawler directory. We saw notable time differences in program execution.
Skills
This project built skills in web crawling, HTML parsing, index construction, and query processing. As the entirety of this project was built in C, we gained a lot of programming, debugging, and UNIX experience.